
GraphQL has off-late become the de facto standard for servers to offer APIs to clients.
APIs have mostly been built around the REST architecture, where the server represents a collection of resources and provides clients with the ability to access and manipulate these resources using HTTP methods (GET, PATCH, DELETE, etc.).
While REST APIs are still an excellent pattern for building APIs, GraphQL takes a different approach. In this paradigm, the server provides access to the objects using a graph-like structure. The server defines a schema, which references types (analogous to resources in REST APIs), which in turn have fields containing values. The schema exports a graph-like structure, with the so-called root type at the top level, from where the nesting starts.
GraphQL = Flexibility
One of the biggest advantages of this approach is that it provides the client with a ton of flexibility when asking the server for data.
Let's try to illustrate this with an example. Consider a case where the server
defines Book and Author resources, and we need our API to be able to get all
the authors stored in the database. Also assume that we have two clients, one of
which cares only about the author details, and the other one also wants to know
about the books that the authors wrote.
In a RESTful architecture, the API would define author and book resources,
accessible through endpoints such as /api/authors that returns all the
authors, and /api/books that returns all the books. With this setup, if we
want /api/authors to additionally include the book information, the API would
have to incorporate some sort of a flag to take this into account. One
implementation might add an include_books query parameter to the URL, such
that the client sends a request to /api/authors/?include_books=true to get the
required information. This solves the problem, but the query parameter approach
looks a bit awkward.
With GraphQL, the client has the ability to specify exactly what they want,
thereby eliminating the whole problem. Assuming that the API defines author
and book types, a GraphQL query to fetch the information we need might look as
follows:
query {
authors {
first_name
last_name
books {
name
published_at
}
}
}
No query parameters, no special casing, just one query that gets the job done.
Starlette + GraphQL = 🍓
There are a few different libraries that let us build GraphQL support into a Starlette application.
One of the rather popular ones is called Strawberry 🍓. Strawberry integrates quite well with Python web frameworks. There's also very good support for ASGI frameworks, which means we're off to a good start with Starlette.
Let's use Strawberry to add GraphQL support to a basic Starlette application. As always, here's a minimal Starlette application:
from starlette.applications import Starlette
from starlette.endpoints import HTTPEndpoint
from starlette.routing import Route
from starlette.requests import Request
from starlette.responses import Response
class HelloEndpoint(HTTPEndpoint):
def get(self, request: Request):
return Response("<h1>Hello, World!</h1>")
instance = Starlette(
routes=(
Route("/hello", HelloEndpoint, name="hello"),
),
)
Put the code above in a file called main.py and run it using uvicorn main:instance --port 8000. You should be able to access
http://localhost:8000/hello in your browser and see the spectacular "Hello,
World!" message written across the screen.
Add a Schema
In GraphQL, everything starts with a Schema. A Schema defines what the client sees and is able to query. So let's add a basic schema to our application.
from starlette.applications import Starlette
from starlette.endpoints import HTTPEndpoint
from starlette.routing import Route
from starlette.requests import Request
from starlette.responses import Response
import strawberry
from strawberry.asgi import GraphQL
@strawberry.type
class Query:
pass
class HelloEndpoint(HTTPEndpoint):
def get(self, request: Request):
return Response("<h1>Hello, World!</h1>")
instance = Starlette(
routes=(
Route("/hello", HelloEndpoint, name="hello"),
),
)
schema = strawberry.Schema(Query)
graphql_app = GraphQL(schema)
instance.add_route("/graphql", graphql_app)
instance.add_websocket_route("/graphql", graphql_app)
In this snippet, we've defined a Query class that's marked as a
strawberry.type. This type will serve as a starting point for all the types
we'll add later on. We then use this class to instantiate a strawberry.Schema
object, create a strawberry.asgi.GraphQL app using the schema, and link the
GraphQL app to our original starlette.applications.Starlette application
instance.
With this in place, the /graphql endpoint will now serve as the main point of
entry for clients to our GraphQL API on the server.
At this point, we have added an empty schema, but the server should refuse to start with the error message: "❌ Type Query must define one or more fields.".
The error message tells us exactly what's wrong. Our schema needs to define something that can be returned back to the client. So let's do that next.
Add a Query
Let's modify the Query type to add a message field which returns a plain
string.
import strawberry
def resolve_message() -> str:
return "Hello!"
@strawberry.type
class Query:
message: str = strawberry.field(resolver=resolve_message)
This snippet adds a message field to our schema, the value of which resolves
to "Hello!" using a simple resolve_message resolver function. Note that there
are a few different ways of defining resolvers using Strawberry, in case you'd
like to define it differently. We'll change the field to something useful in the
next section, but for now this should suffice as an example of how a field can
be defined.
Run the code again using uvicorn and access http://localhost:8000/graphql in
the browser. This time you should see GraphiQL (pronounced "graphical") which
is a built-in interface shipped with most GraphQL libraries for running GraphQL
queries (or mutations) that makes it easier to debug things. It provides for a
REPL-like workflow where you can enter queries on the left and see the
evaluation results on the right.
Enter the following query in the pane on the left:
query {
message
}
... and click on the pink "Play" button to execute the query. The results of the query execution should be displayed in the results pane on the right, as shown in the following screenshot:
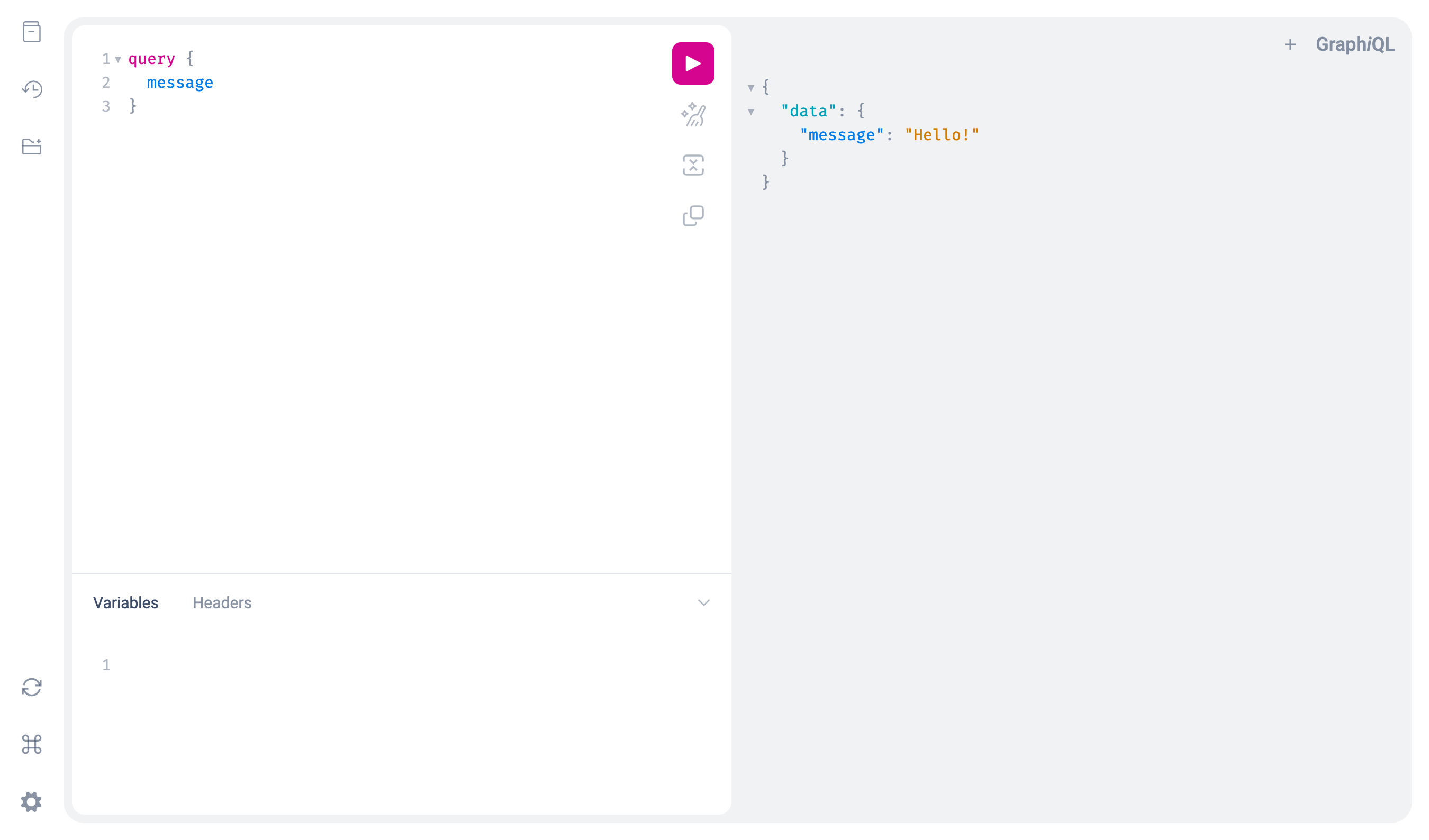
Wonderful! At this point, we have a minimal yet functional GraphQL API in our Starlette application.
As you've probably noticed, the message always returns the same value, which is not very useful in a real-world application. Let's fix that next by adjusting our query type definition.
Resolving the current user
In this section, we'll change the message field from earlier to something more
useful.
Let's add a currentUser field that returns the details of the currently logged
in user. In web application, clients often need to get the details of the user
that's currently logged in. So this should serve as a good example for how a
real-world query could look like.
from datetime import datetime
from typing import Optional
import strawberry
from strawberry.types import Info
@strawberry.type
class User:
email: str
first_name: str
last_name: str
created_at: datetime
def resolve_current_user(root: User, info: Info) -> Optional[User]:
request = info.context["request"]
user = get_user_from_database(request)
if not user:
return None
return User(
email=user.email,
first_name=user.first_name,
last_name=user.last_name,
created_at=user.created_at,
)
def resolve_message() -> str:
return "Hello!"
@strawberry.type
class Query:
message: str = strawberry.field(resolver=resolve_message)
current_user: User = strawberry.field(resolver=resolve_current_user)
There's quite a bit going on in this snippet. We first define a User type with
a few important fields. This is the type that will be exposed to the clients
over GraphQL. Next, we've added a resolve_current_user resolver function. This
is the function that takes in the parent object and the current execution
context (we'll come to what that means in a bit) and returns a User object if
one could be located, which will eventually be sent back to the client.
And finally, we've adjusted the Query type to add a current_user field which
is resolved using the resolve_current_user resolver.
The resolver function takes two special parameters that deserve a call out.
root: this represents the parent object in the current context. Since GraphQL defines a parent/child relationship between objects in the API, any value being queried will always have a parent, which is what therootparameter represents. In our example, the parent isNoneas we're performing the query at the top level.info: sometimes we want to be able to pass information related to the [current execution]. This is where theinfoparameter comes in. Theinfo.contextfield is especially relevant for us, because Strawberry/ASGI populates it with arequestkey, accessing which gives us the current HTTP request object. This is useful because if we have the HTTP request information, we can take a look at the cookies or the request headers to be able to identify the current user.
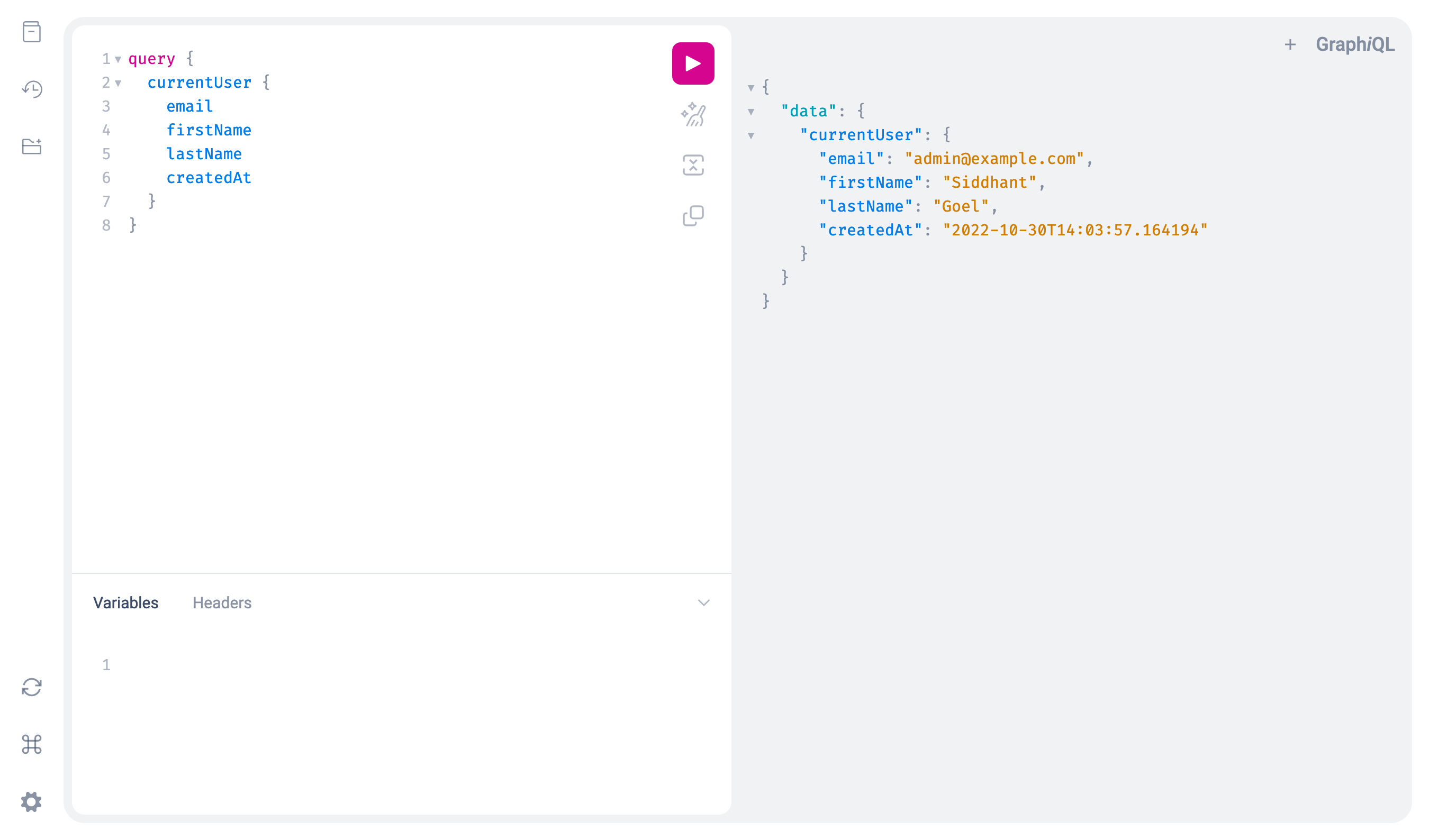
With all this in place, clients should be able to run a query like this to get the current user:
query {
currentUser {
email
first_name
last_name
created_at
}
}
And indeed, if you run this query in GraphiQL, you should get all the requested information as shown in the following screenshot:
Conclusion
GraphQL is a different paradigm as compared to RESTful APIs. Accordingly, the patterns used in the GraphQL world are different from what we're used to from before.
In this blog post, we looked at one such pattern relating to how to query specific data from the server. We looked at how to define an empty schema, then extended it with a field that returns a static value, and then extended it with a field that returns values based on who the requestor is.
In one of the next blog posts, we'll look at how to define mutations (which allow clients to modify data on the server) and subscriptions (which allow clients to receive information from the server in real-time). Until then, happy building! 🏗
All code you see in this article is freely available on our Github: https://github.com/geniepy/snippets/tree/main/blog/starlette-graphql.